Case Study: De-coupling application from infrastructure deployment pipelines
Recently I was tasksed with assessing the application deployment pipelines and associated infrastructure deployments for a client I'm working with.
Their current deployment process looks something like this:
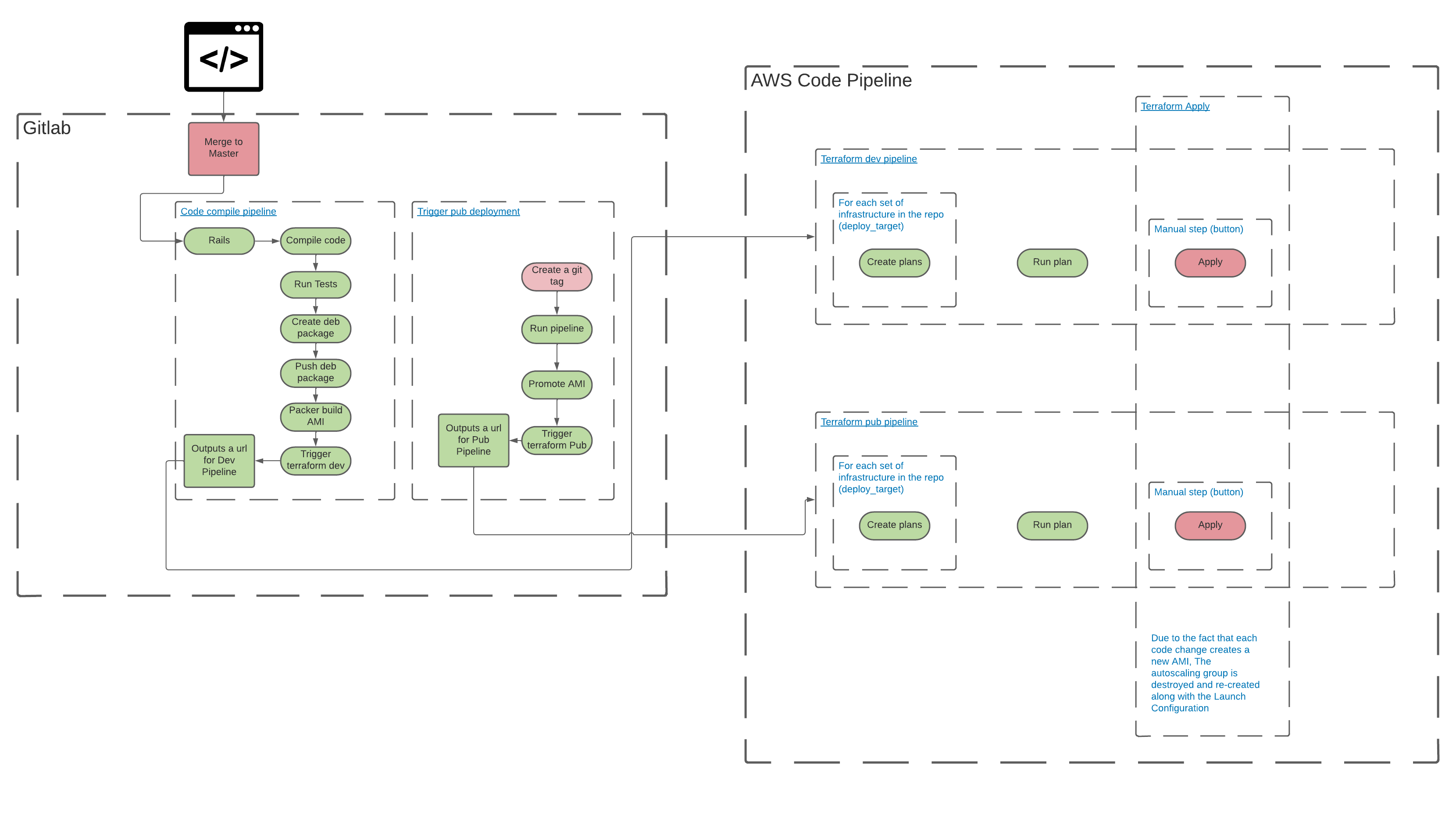
The application in question here is a ruby web application. As you can see from the digram the application is initially compiled and built into a .deb package which is then installed into an ubuntu based Amazon Machine Image using packer. This AMI is then uploaded to Amazon Web Services. The final step of the application pipeline is to trigger an AWS Code Pipeline which in turn runs a terraform plan and apply which then replaces the auto scaling group and associated launch configurations to utilise the newly created AMI.
The Problem
There are a number of reasons why this approach is not ideal:
- Replacing the auto scaling group causes down time
- Not utilising the autoscaling groups ability to replace nodes in line
- An incorrectly built AMI could cause the terraform apply command to fail and thus potentially cause infrastructure failure.
- Time to deployment is very long, building a full AMI every time a change is made to the application code along with running a full terraform apply, in effect destroying and re-creating an entire Auto Scaling Group Launch Configuration and associated EC2 instances takes a LONG time.
The propsed solution
The first point to address was the building of the AMI. In my opinion this is not needed and can be replaced with something a little more versatile CONTAINERISATION! Given the fact that the client already has existing skills around containers/docker etc there will be minimal upskilling required to move the developers away from the existing process into a leaner container build process.
The packer AMI build step can literally be lifted and replaced with a docker build step, keeping the existing .deb package and simply running an apt update && apt install {packagename} during the container build step.
With the deprication of AMI's in favour of containerisation a number of possiblities for infrastructucure are now available. These decisions are however, just like the decision to move to containers, heavily dependant on existing skills within the business.
The options considered were:
- Full Fat Kubernetes
- EKS
- ECS
ECS was chosen mainly due to the existing skills within the business, it was decided that the move to something like Kubernetes would take too long to upskill existing engineers whereas something like ECS is a nice middle-ground given that the engineers already had minimal experience with similar orchestration system (docker swarm).
This introduces a number of changes to the deployment pipeline process, illustrated below:
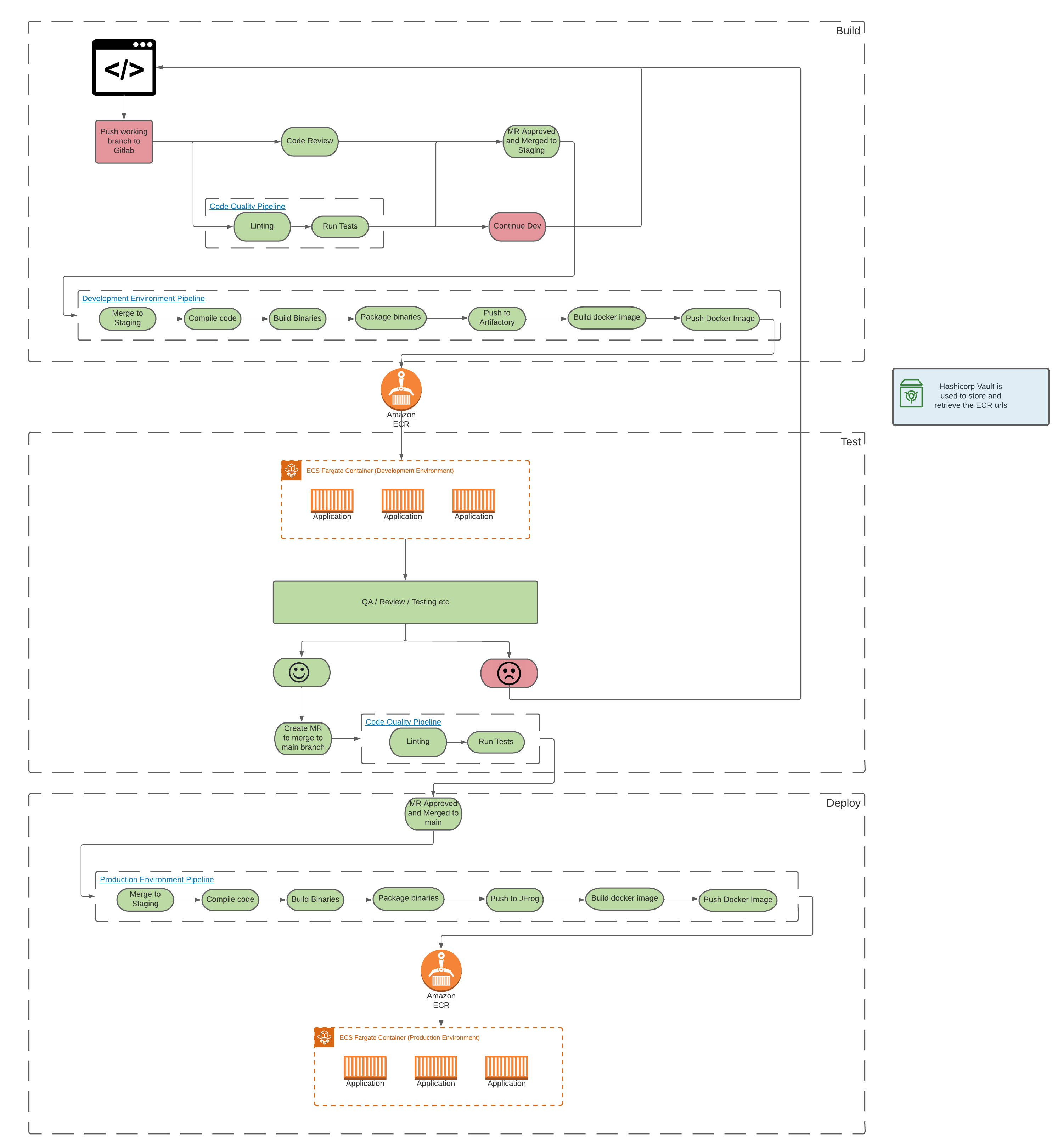
The proposed process splits the pipeline into build, test, deploy stages. Each of which can be replicated to target a specific environment (dev, sit, uat, prod for example). Each stage has it's own set of infrastructure specific to that environment.
Build pipeline
The Build pipeline is triggerd by merging a working branch into the staging branch. Additionally any push to the repository triggers a Code Quality Pipeline which runs parralel and allows for linting and code quality checks to take place. If the Code Quality Pipeline fails the Merge Request becomes void and errors must be fixed before merging into Staging is allowed. Once code has been reviewed, approval of the MR will trigger the Build pipeline.
The main changes here as we can see is the replacement of the packer build step with a Build Docker image step and additionaly a Push Docker step. The Developers have control over the Dockerfile for the application and the docker registry (ECR) url for the docker push command is retrieved dynamically from a self hosted Hashicorp Vault instance.
An image tagging mechanism has been introduced to handle refreshing of the of the images running within the ECS Service Definition. Each environment has it's own image tag, for example myimage:dev or myimage:uat. If a rollback is required this can be triggered via a branch revert within gitlab and additionally triggering the deployment pipeline again for any given environment.
The new infrastructure
As we are now working with containers instead of AMIs a complete redesign of the infrastructure was required. The Proof Of Concept Infrastructure was designed in such a way to provide the developers with a so called "backend" service and a "frontend" service. This enabled demonstration of passing seperate environment variables per service, per environment and enabling specific routing via security group rules between the internal services.
The diagram below details an overview of the infrastructure described in terraform:
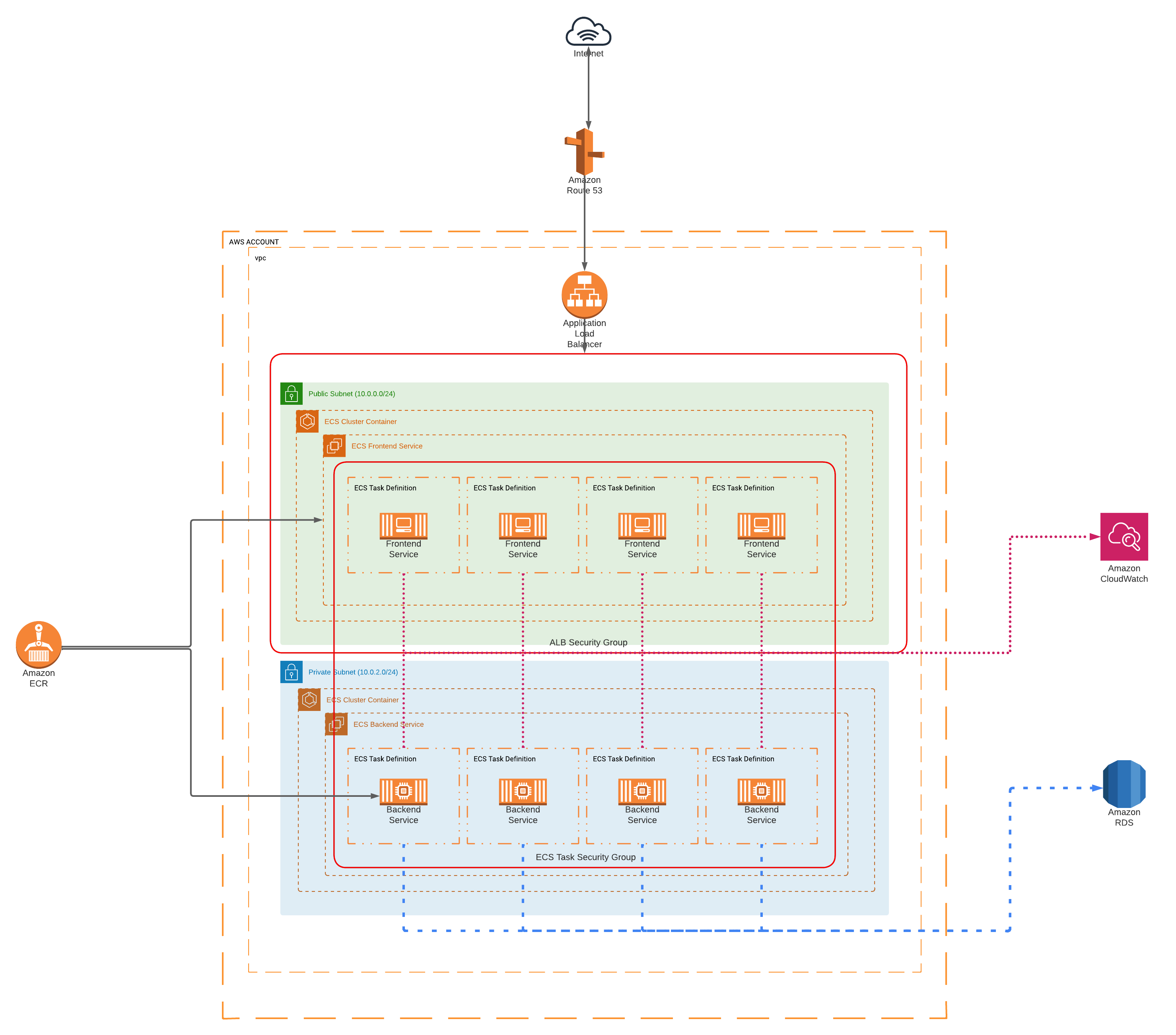
The client utilises an account per environment structure, this means, for example they have an AWS account specificly for Development environments and a entirely seperate AWS account for Production. This is shown in the digram by the AWS ACCOUNT grouping, and within that an account-wide VPC.
As this is a Proof Of Concept the number of Tasks within each service is fixed and there is no concept of auto-scaling. Going forward this would be addressed. There is however, a mechanism where the developers are able to pass json into the task defition allowing them to specify the details per container to be run within each task (environment variables, memory/cpu requirements etc).
The seperation of frontend and backend services within public and private subnets introduces 'By Design' protection of backend services, communication is controlled via security group rules via Load Balancer specific Security Group and a ECS Task specific Security group. This allows for strict control over how each internal services and external clients communicate as well as backend to storage/database - in the case of the PoC here an RDS instance.
Conclusion
The developers now have a robust way of testing their applications locally with Docker. Previously they would debug locally in a varying envrionments from Windows machines to MacOs. Now they're testing locally with the same base docker image that runs in production which means a massive reduction in the number of unknowns between developer and deployment.
De-coupling the application from the infrastructure has not only increased the frequency in which the developers can deploy to any given environment. It has reduced down time to zero as we are now off-loading the quorum of services to ECS.